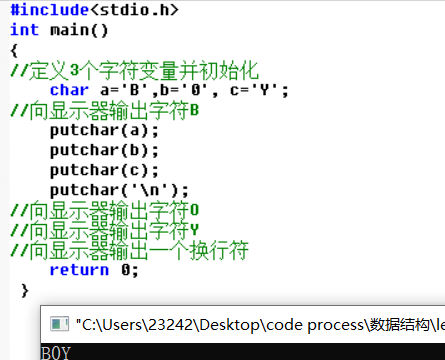
实例:C语言编程题
求100到300之间所有素数
1 |
|
预备计算机知识
汇编语言是最低级的语言,它可以直接与硬件打交道。高级语言有Pascal、Basic、Fortran等等。高级语言的一条语句对应低级语言的很多条语句,任何高级语言编写的程序都要经过编译程序的编译、连接才能成为可以运行的程序。
编译连接的过程也就是把高级语言翻译成机器语言(二进制机器码)的过程,而汇编语言是基本上与机器语言一 一对应的一种语言。这个翻译过程是由编译程序自动完成的。把C语言定为中级语言是有它的道理的,因为C语言既有汇编语言的存取底层硬件的能力,又具有高级语言的许多特点。熟练掌握了C语言,学习其它的各种编程语言应该是很轻松的了。
C语言的书写格式:
1) 一个C语言编写的源程序,必定有一个主程序(称为main()函数,在C语言中子程序称为“函数”(当然,不要理解成为数学里面的“函数”)。但是决不能有一个以上的main函数(即只能有一个)。
2) 函数语句块用‘{’括号开始, 以‘}’反括号结束。这样的花括号必须成对出现。
3) 表达式写在小括号里面,以‘(’括号开始,以‘)’反括号结束。
4) 函数不能嵌套,即函数里面不能再套函数。(每一个函数是完成一个特定功能的函数模块)
C语言的组成:
C语言是由许多函数组成的。其中只有一个主函数(main()函数)。C程序执行时总是从main函数的‘{’处开始,至main函数的反大括号’}’处结束。当然还有其它一些规则,这将在以后的学习中去熟悉它。
C语言的书写规则:
C语言在书写时有它自身的特点:书写格式比较自由,在一行里可以写多条语句,一个语句也可以分写在多行上。虽然如此,在书写源程序时还是要注意哪些可以自由书写,而哪些必须要按照书写规则来书写。
几条规则写在下面:
1) 一行内可以写几个语句,建议一行不超过两条语句;
2) 一条语句可以写在多行上;
3) C语句不需要写行标号;
4) 每条语句及数据定义的后面要写上分号以表示该语句结束;
5) C语言中注释用 //来表示;
6) 建议书写时采用缩进格式;
7) 花括号、小括号都是成对出现的。
一个最简单的C程序的编写:
/程序代码/ /注释部分/
main() /main是主函数名。紧跟在main后面的括号是放参数的。
括号里面为空说明main函数不需要参数/
{ /正写的大花括号表示main函数从这里开始/
} /反写的大花括号表示main函数到这里结束/
说明:由于是一个演示程序,在函数体内并没有任何可以执行的语句,也就是这个程序什么事也不做。
这个程序就是这么简单: 写在一行上就是 main() { }
你在TC的编辑环境下把这段代码输入进去,按F9键编译连接,按CTRL_F5运行,一定很正常。但是什么结果也不会有,因为在main函数里面什么代码也没有。
下面再举一个可以向屏幕上输出一条信息的例子:
main()
{
printf(“这就是C语言编写的程序!”); /这一条语句的作用是向屏幕输出一条信息
”这就是C语言编写的程序!”/
}
在这个程序中,main函数只有一条语句:printf(“这就是C语言编写的程序!”);这个语句的作用是向屏幕输出一个字符串。有关这个语句的知识以后再讲。现在要注意的是一个C语言程序的框架是怎样组成的。
C语言程序的几种文件格式:
1、 源程序—在TC集成环境中输入的程序文本称为源程序。源程序是一种文本文件。它是我们看得见并认识的一种文件。其扩展名为.C。例如你把文件保存为TEST,那么在磁盘上应看得到TEST.C这个文件。这样的文件可以用记事本打开。
2、二进制文件—写完了源程序后接着要做的是编译这个文件。在TC集成环境里是按ALT_F9键,编译后生成了一个二进制文件,这个二进制文件名为TEST.OBJ,也就是扩展名为OBJ的目标文件。
3、运行文件—最后一步是make(或Link),在TC集成环境里是按F9键Make之后生成了一个可以在DOS下运行的文件,其扩展名为EXE。如TEST.EXE。这个EXE文件是由第2步中的OBJ文件生成的。
OBJ文件虽然是二进制文件,而电脑又是可以运行二进制文件的,为什么还要把OBJ文件Link为EXE文件才能运行?这里的知识就比较多了,这里不能多讲。
但是要明白一点,在DOS下仅仅有了一个二进制文件还不能运行,因为操作系统要把这些二进制文件加以规划,把相应的数据、程序代码放到应该放的内存位置,这样的经过严密规划和组织好了的二进制文件才能运行。而这些只有在生成的EXE文件里面才做完了这些工作。
1 |
|
输出结果13
1 |
|
输出结果
2f
2F
0X2F
0x2f
2
3
4
5
6
7
8
9
10
11
12
13
14
15
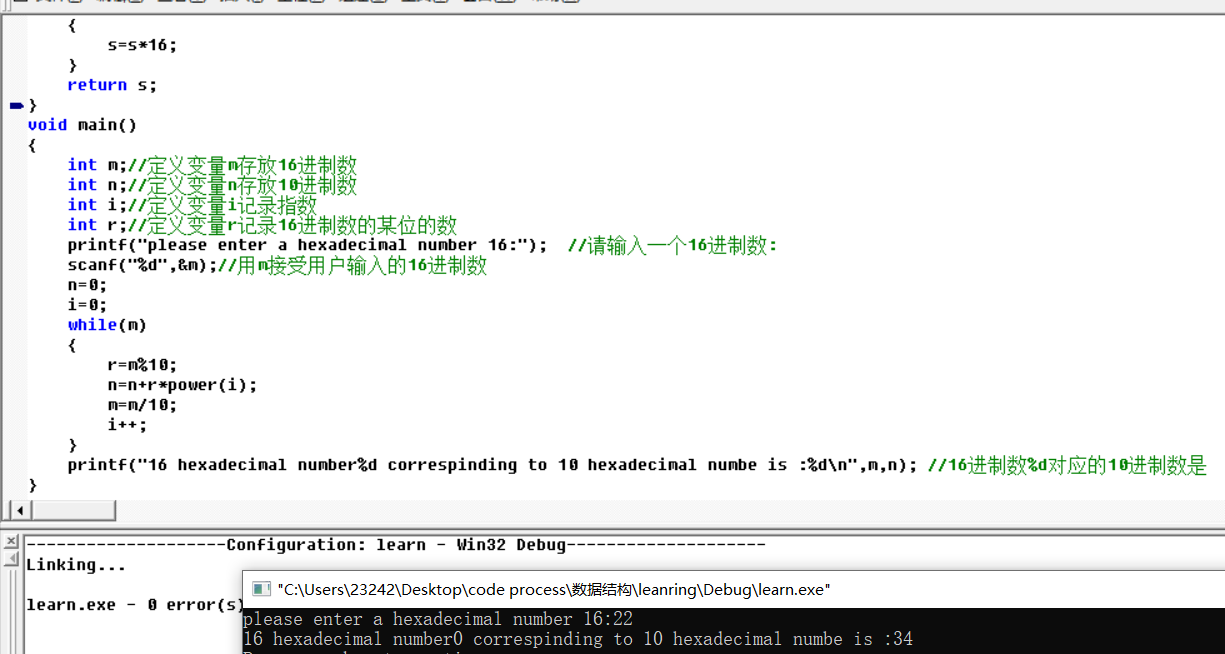
%c 读入一个字符
%d 读入十进制整数
%i 读入十进制,八进制,十六进制整数
%o 读入八进制整数
%x,%X 读入十六进制整数
%s 读入一个字符串,遇空格、制表符或换行符结束。
%f,%F,%e,%E,%g,%G 用来输入实数,可以用小数形式或指数形式输入。
%p 读入一个指针
%u 读入一个无符号十进制整数
%n 至此已读入值的等价字符数
%[] 扫描字符集合
%% 读%符号
x是1~f,X是1~F
#是带格式输出 例如0x代表十六进制
C语言常见误区
1.书写标识符时,忽略了大小写字母的区别。
2
3
4
5
{
int a=5;
printf("%d",A);
}编译程序把a和A认为是两个不同的变量名,而显示出错信息。C认为大写字母和小写字母是两个不同的字符。习惯上,符号常量名用大写,变量名用小写表示,以增加可读性。
2.忽略了变量的类型,进行了不合法的运算。
2
3
4
5
{
float a,b;
printf("%d",a%b);
}%是求余运算,得到a/b的整余数。整型变量a和b可以进行求余运算,而实型变量不允许进行“求余”运算。
3.将字符常量与字符串常量混淆。
char c;
c=”a”;
在这里就混淆了字符常量与字符串常量,字符常量是由一对单引号括起来的单个字符,字符串常量是一对双引号括起来的字符序列。C规定以“\”作字符串结束标志,它是由系统自动加上的,所以字符串“a”实际上包含两个字符:‘a’和‘',而把它赋给一个字符变量是不行的。
4.忽略了“=”与“==”的区别。
在许多高级语言中,用“=”符号作为关系运算符“等于”。如在BASIC程序中可以写if (a=3) then …但C语言中,“=”是赋值运算符,“==”是关系运算符。如:
if (a==3) a=b;前者是进行比较,a是否和3相等,后者表示如果a和3相等,把b值赋给a。由于习惯问题,初学者往往会犯这样的错误。
5.忘记加分号。
6.多加分号。
7.输入变量时忘记加地址运算符“&”。
int a,b;
scanf(“%d%d”,a,b);
这是不合法的。Scanf函数的作用是:按照a、b在内存的地址将a、b的值存进去。“&a”指a在内存中的地址。
8.输入数据的方式与要求不符。
①scanf(“%d%d”,&a,&b);输入时,不能用逗号作两个数据间的分隔符,如下面输入不合法:3,4输入数据时,在两个数据之间以一个或多个空格间隔,也可用回车键,跳格键tab。
②scanf(“%d,%d”,&a,&b);C规定:如果在“格式控制”字符串中除了格式说明以外还有其它字符,则在输入数据时应输入与这些字符相同的字符。下面输入是合法的:
3,4此时不用逗号而用空格或其它字符是不对的。
3 4 3:4
又如:scanf(“a=%d,b=%d”,&a,&b);输入应如以下形式:a=3,b=4
9.输入字符的格式与要求不一致。
在用“%c”格式输入字符时,“空格字符”和“转义字符”都作为有效字符输入。
scanf(“%c%c%c”,&c1,&c2,&c3);如输入a b c字符“a”送给c1,字符“ ”送给c2,字符“b”送给c3,因为%c只要求读入一个字符,后面不需要用空格作为两个字符的间隔。
10.输入输出的数据类型与所用格式说明符不一致。
例如,a已定义为整型,b定义为实型,a=3;b=4.5;printf(“%f%d\n”,a,b);编译时不给出出错信息,但运行结果将与原意不符。这种错误尤其需要注意。
11.输入数据时,企图规定精度。scanf(“%7.2f”,&a);这样做是不合法的,输入数据时不能规定精度。
12.switch语句中漏写break语句。
例如:根据考试成绩的等级打印出百分制数段。
2
3
4
5
6
{ case 'A':printf("85~100\n");
case 'B':printf("70~84\n");
case 'C':printf("60~69\n");
case 'D':printf("<60\n");
default:printf("error\n");由于漏写了break语句,case只起标号的作用,而不起判断作用。因此,当grade值为A时,printf函数在执行完第一个语句后接着执行第二、三、四、五个printf函数语句。正确写法应在每个分支后再加上“break;”。例如case ‘A’:printf(“85~100\n”);break;
13.忽视了while和do-while语句在细节上的区别。因为while循环是先判断后执行,而do-while循环是先执行后判断。
14.定义数组时误用变量。
2
3
scanf("%d",&n);
int a[n];数组名后用方括号括起来的是常量表达式,可以包括常量和符号常量。即C不允许对数组的大小作动态定义。
15.在定义数组时,将定义的“元素个数”误认为是可使的最大下标值。
2
3
4
{static int a[10]={1,2,3,4,5,6,7,8,9,10};
printf("%d",a[10]);
}C语言规定:定义时用a[10],表示a数组有10个元素。其下标值由0开始,所以数组元素a[10]是不存在的。
16.在不应加地址运算符&的位置加了地址运算符。scanf(“%s”,&str);C语言编译系统对数组名的处理是:数组名代表该数组的起始地址,且scanf函数中的输入项是字符数组名,不必要再加地址符&。应改为:scanf(“%s”,str);
17.同时定义了形参和函数中的局部变量。
2
3
4
5
int x,y,z;
{z=x>y?x:y;
return(z);
}形参应该在函数体外定义,而局部变量应该在函数体内定义。应改为:
2
3
4
5
6
int x,y;
{int z;
z=x>y?x:y;
return(z);
}
1 |
|
1
2
3
2
1.在主函数main中,定义了第一个整形变量,为其赋值为1,赋值后使用printf函数输出变量。在程序的运行结果中可以看到,此时的iNumber的值为1
2.使用if语句进行判断,这里使用if语句的目的在于划分出一段语句块。因为位于不同作用域的变量可以使用相同的标示符,所以在if语句块中也定义一个iNumber变量,并为其赋值为2.再次使用printf函数输出变量,观察运行结果,发现第二个输出的值为2.此时值为2的变量在此作用域中就将值为1的变量屏蔽掉。
IF语句
语法格式为:
2
3
4
5
语句1;
else
语句2;
语句3;NS图表示如下:
2
3
4
5
6
7
8
9
| 表达式 |
|------|-----|
| 真 | 假 |
|------|-----|
|语句1 |语句2|
|------------|
| 语句3 |
|------------|
语句解释:对表达式1进行判断,结果为真(非0)时则执行语句1,若为假(为0)则执行语句2,完成执行后退出if并执行if后的语句3。
1 |
|
[1]: 3, 2, 1
3,5,12
[3] 3,2,1
基本的输入与输出
int scanf(const char \*format, arg_list)
scanf主要从标准输入流中获取参数值,format为指定的参数格式及参数类型,如scanf("%s,%d",str,icount);
它要求在标准输入流中输入类似”son of bitch,1000”这样的字符串,同时程序会将”son of bitch”给str,1000给icount.
scanf函数的返回值为int值,即成功赋值的个数,在上例中如果函数调用成功,则会返回2,所以我们在写程序时,可以通过
语句if(scanf("%s,%d",str,icount) != 2){...}来判断用户输入是否正确.
int printf(const char *format, arg_list)
printf主要是将格式化字符串输出到标准输出流中,在stdio.h头文件中定义了标准的输入和输出,分别是stdin,stdout.
arg_list可以是变量名,也可以是表达式,但最终都会以值的形式填充进format中.
int getc(FILE \*fp)
getc主要是从文件中读出一个字符.常用的判断文件是否读取结束的语句为:(ch = getc(fp)) != EOF,EOF为文件结束标志,定义在stdio.h中,就像EXIT_SUCCESS,EXIT_FAILURE定义在stdlib.h中一样,文件也可以被理解为一种流,所以当fp为stdin时,getc(stdin)就等同于getchar()了.
int putc(int ch,FILE \*fp)
putc主要是把字符ch写到文件fp中去.如果fp为stdout,则putc就等同于putchar()了.
int getchar(void)
getchar主要是从标准输入流读取一个字符.默认的标准输入流即stdio.h中定义的stdin.但是从输入流中读取字符时又涉及到缓冲的问题,所以并不是在屏幕中敲上一个字符程序就会运行,一般是通过在屏幕上敲上回车键,然后将回车前的字符串放在缓冲区中,getchar就是在缓冲区中一个一个的读字符.当然也可以在while循环中指定终止字符,如下面的语句:while ((c = getchar()) != '#')这是以#来结束的.
int putchar(int ch)
putchar(ch)主要是把字符ch写到标准流stdout中去.
char * gets(char \*str)
gets主要是从标准输入流读取字符串并回显,读到换行符时退出,并会将换行符省去.
int puts(char \*str)
puts主要是把字符串str写到标准流stdout中去,并会在输出到最后时添加一个换行符.
char *fgets(char \*str, int num, FILE \*fp)
str是存放读入的字符数组指针,num是最大允许的读入字符数,fp是文件指针.fgets的功能是读一行字符,该行的字符数不大于num-1.因为fgets函数会在末尾加上一个空字符以构成一个字符串.另外fgets在读取到换行符后不会将其省略.
int fputs(char \*str, file *fp)
fputs将str写入fp.fputs与puts的不同之处是fputs在打印时并不添加换行符.
int fgetc(FILE \*fp)
fgetc从fp的当前位置读取一个字符.
int fputc(int ch, file \*fp)
fputc是将ch写入fp当前指定位置.
int fscanf(FILE \*fp, char \*format,...)
fscanf按照指定格式从文件中出读出数据,并赋值到参数列表中.
int fprintf(FILE \*fp, char \*format,...)
fprintf将格式化数据写入流式文件中.
1 |
|
1 |
|
ASCII码
ASCII ((American Standard Code for Information Interchange): 美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是最通用的信息交换标准,并等同于国际标准ISO/IEC 646。ASCII第一次以规范标准的类型发表是在1967年,最后一次更新则是在1986年,到目前为止共定义了128个字符。
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号,以及在美式英语中使用的特殊控制字符 。其中:
0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符),如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(响铃)等;
通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;
ASCII值为8、9、10 和13 分别转换为退格、制表、换行和回车字符。它们并没有特定的图形显示,但会依不同的应用程序,而对文本显示有不同的影响。
32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
同时还要注意,在标准ASCII中,其最高位(b7)用作奇偶校验位。所谓奇偶校验,是指在代码传送过程中用来检验是否出现错误的一种方法,一般分奇校验和偶校验两种。奇校验规定:正确的代码一个字节中1的个数必须是奇数,若非奇数,则在最高位b7添0;偶校验规定:正确的代码一个字节中1的个数必须是偶数,若非偶数,则在最高位b7添1。
后128个称为扩展ASCII码。许多基于x86的系统都支持使用扩展(或“高”)ASCII。扩展ASCII 码允许将每个字符的第8 位用于确定附加的128 个特殊符号字符、外来语字母和图形符号。
1 |
|
65
不同数据类型之间的赋值问题
- 各类数值型数据间混合运算时的类型转换规则
整型、实型、字符型数据间可以混合运算。在这种情况下,需要将不一致的数据类型转
换成一致的数据类型,然后进行运算。为了保证运算精度,系统在运算时的转换规则是将存储长度较短的运算对象转换成存储长度较长的类型,然后再进行处理。
如float型数据必先转换为double型数据,然后与其他操作数进行运算。与此类似,char型或short型数据必先转换为int型数据,然后进行运算。
如int型数据与unsigned型数据进行运算,int型转换为unsigned型后方可进行运算。int型数据与double型数据进行运算,int型直接转换为double型后进行运算,不能理解为先转换为unsigned int型,然后转换为long int型,最后再转换为double型。
赋值时的类型转换
当赋值运算符两侧的类型不同时,需进行类型转换,这种转换也是系统自动进行的。具体转换原则如下:
1)float、double型赋值给int型:直接截断小数。
例如:int i=f+0.6; f的值4.0,右边算术表达式运算后的结果为一个值为4.6的double型数据,根据上述转换原则,直接舍弃小数,所以i的值为4。
2)int、char型赋值给float、double型:补足有效位以进行数据类型转换。
例如:float f=4; float为7位有效数字,所以f的值为4.000000。
3)char型(1字节)赋值给int型(2字节):数值赋给int的低8位,高8位补0。
4)long int型赋值给int型:long int截断低字节给int型。
5)int 型赋值给long int:赋给long int的低16位,如果int的最高位是0,则long int的高16位全为0;如果int的最高位是1,则long int的高8位全为1(称为“符号扩展”)。
6)unsigned int型赋值给int型:直接传送数值。
7)非unsigned数据型赋值给位数相同的unsigned 数据:直接传送数值
强制类型转换
除了以上的两种自动类型转换外,在C语言中,允许强制类型转换,将某一数据的数据类型转换为指定的另一种数据类型。强制转换是用强制转换运算符进行的,强制转换运算符为:(类型名),强制转换运算符组成的运算表达式的一般形式为:
(类型名)(表达式)
例如:
(int)(x + y) //将x+y的值转换成整型,即取整数部分。
(float)x + y //将x转换成单精度型。
强制转换运算符优先级比算术运算符高。同表达式中数据类型的自动转换一样,强制类型转换也是临时转换,对原运算对象的类型没有影响。
例如,已知有变量定义:int b=7;float a=2.5,c=4.7;求下面算术表达式的值。
a+(int)(b/3(int)(a+c)/2.0)%4;
根据运算符结合性规则,上述表达式要自左之右执行,b/3为2,2int(a+c)为14,14/2.0为7.0,强制类型转换后为7,7%4为3;a的值2.5与3相加,最终结果为5.5。**
1 |
|
1 | #include <stdio.h> |
1 |
|
while
C语言循环控制语句提供了 while语句、do-while语句和for语句来实现循环结构。
while循环语句
一般形式如下:
while(表达式)
语句
do-while语句
一般形式如下:
do语句while(表达式);
do-while循环是先执行语句,然后对表达式求值。若值为真,则再次执行语句,如此反复执行,否则将结束循环。语句可以是简单语句,也可以是复合语句。
for语句
for语句是循环控制结构中使用最广泛的一种循环控制语句,特别适合已知循环次数的情况。
一般形式如下:
for ( [表达式 1]; [表达式 2 ]; [表达式3] )语句
其中:
表达式1:一般为赋值表达式,给控制变量赋初值;
表达式2:关系表达式或逻辑表达式,循环控制条件;
表达式3:一般为赋值表达式,给控制变量增量或减量;
语句:循环体,当有多条语句时,必须使用复合语句。
其执行过程如下:首先计算表达式1,然后计算表达式 2。若表达式2为真,则执行循环体;否则,退出 for循环,执行for循环后的语句。如果执行了循环体,则循环体每执行一次,都计算表达式3,然后重新计算表达式2,依此循环,直至表达式 2的值为假,退出循环。
for语句的三个表达式都是可以省略的,但分号“;”绝对不能省略。for语句有以下几种格式:
(1)for(; ;) 语句;
(2)for(;表达式2;表达式3 ) 语句;
(3)for(表达式1;表达式2;) 语句;
(4)for(i=1,j = n; i < j; i ++,j - - ) 语句;
三种语句比较
同一个问题,往往既可以用 while语句解决,也可以用 do-while或者for语句来解决,但在实际应用中,应根据具体情况来选用不同的循环语句。选用的一般原则是:
(1) 如果循环次数在执行循环体之前就已确定,一般用 for语句。如果循环次数是由循环体的执行情况确定的,一般用 while语句或者do- while语句。
(2) 当循环体至少执行一次时,用 do-while语句,反之,如果循环体可能一次也不执行,则选用while语句。
C++/C循环语句中,for语句使用频率最高,while语句其次,do语句很少用。
三种循环语句for、while、do-while可以互相嵌套自由组合。但要注意的是,各循环必须完整,相互之间绝不允许交叉。
其他循环语句
多重循环结构
在多重循环中,如果有可能,应当将最长的循环放在最内层,最短的循环放在最外层,以减少CPU跨越循环层的次数。
一个循环体内又包含另一个完整的循环结构
三种循环可互相嵌套,层数不限
外层循环可包含两个以上内循环,但不能相互交叉

1 | c语言32个关键字 |
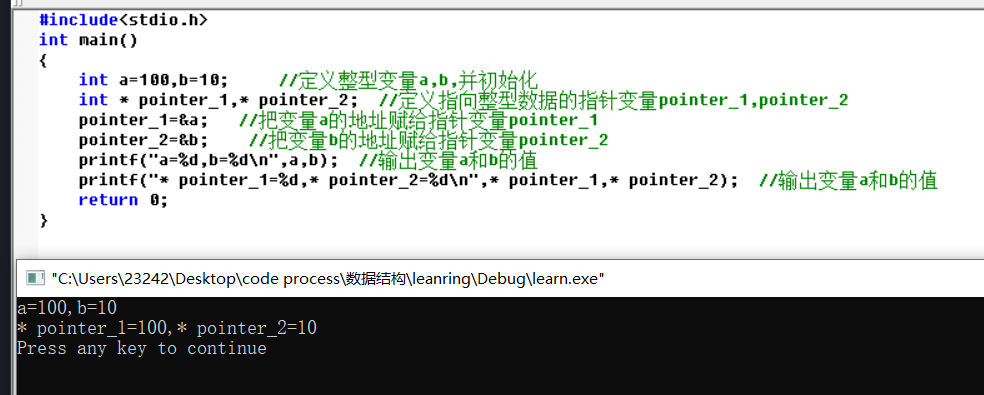
指针
1.定义方法
形式:
类型标识符变量标识符;
定义存放指定类型数据地址的指针变量。
类型标识符是定义指针的基类型,给出指针数据对应存储单元所存放的数据的类型,一般用“指向”这个词来说明这种关系,即类型标识符给出指针所指向的数据类型,可以是简单类型,也可以是复杂类型。用“”表示定义的是指针变量,不是普通变量。变量标识符给出的是指针变量名。
例如:
(1)Int p1,p2,p3;
定义指向整型数据的指针变量p1、p2、p3。
(2)float *q1,q2,q3;
定义指向实型数据的指针变量q1、q2、q3。
(3)charr1,r2,r3;
定义指向字符型数据的指针变量r1、r2、r3。
(4)struct date
{int year;
int month;
int day;
}*t1, *t2, *t3;
定义指向struct date类型数据的指针变量t1、t2、t3。
2.指针变量所指向的变量特定类型的数据
定义的指针变量用于存放指向类型数据的地址,我们可以通过指针运算“”,引用指针变量所指向的数据。有关内容我们在指针运算中加以介绍。
例如,对指针变量p1、p2、p3,假定已有值,\p1、p2、p3代表指针变量p1、p2、p3所指向的数据,也就是p1、p2、p3的值对应的存储单元里存放的数据,称为指针变量所指向的变量,简称指针指向变量。
指针类型也是一种复杂类型,指针指向变量可以认为是指针数据的分量。指针指向变量相当于基类型变量。
如果指针变量p1、p2、p3分别存放整型变量i、j、k的地址,则p1指向i,p2指向j,p3指向k。
1 |
|
函数
一、无参函数的定义形式
类型标识符 函数名()
{
声明部分
语句
}
其中类型标识符和函数名称为函数头。类型标识符指明了本函数的类型,函数的类型实际上是函数返回值的类型。该类型标识符与前面介绍的各种说明符相同。函数名是由用户定义的标识符,函数名后有一个空括号,其中无参数,但括号不可少。
{}中的内容称为函数体。在函数体中声明部分,是对函数体内部所用到的变量的类型说明。
在很多情况下都不要求无参函数有返回值,此时函数类型符可以写为void。
我们可以改写一个函数定义:
void Hello()
{
printf (“Hello,world \n”);
}
这里,只把main改为Hello作为函数名,其余不变。Hello函数是一个无参函数,当被其它函数调用时,输出Hello world字符串。
二、有参函数定义的一般形式
类型标识符 函数名(形式参数表列)
{
声明部分
语句
}
有参函数比无参函数多了一个内容,即形式参数表列。在形参表中给出的参数称为形式参数,它们可以是各种类型的变量,各参数之间用逗号间隔。在进行函数调用时,主调函数将赋予这些形式参数实际的值。形参既然是变量,必须在形参表中给出形参的类型说明。
例如,定义一个函数,用于求两个数中的大数,可写为:
int max(int a, int b)
{
if (a>b) return a;
else return b;
}
第一行说明max函数是一个整型函数,其返回的函数值是一个整数。形参为a,b,均为整型量。a,b的具体值是由主调函数在调用时传送过来的。在{}中的函数体内,除形参外没有使用其它变量,因此只有语句而没有声明部分。在max函数体中的return语句是把a(或b)的值作为函数的值返回给主调函数。有返回值函数中至少应有一个return语句。
在C程序中,一个函数的定义可以放在任意位置,既可放在主函数main之前,也可放在main之后。
1 |
|
数组
1、数组的概念、定义和使用
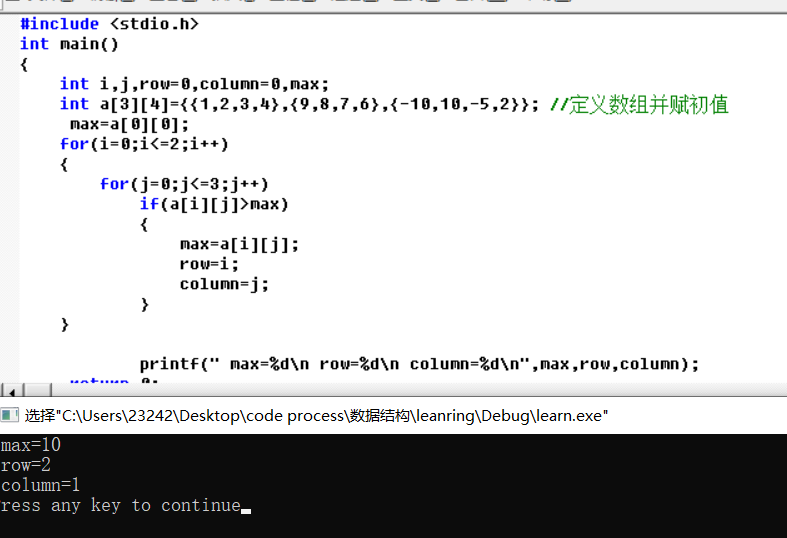
数组(array)是C语言中用于组合同类型数据对象的机制。一个数组里汇集一批对象(数组元素)。程序中既能从数组出发处理其中的个别元素,也能以统一方式处理数组的一批元素或所有元素。后一处理方式特别重要,是由一批成员构成的数组和一批独立命名的变量间的主要区别。数组机制要解决三个问题:)描述数组的性质,定义数组变量; )使用数组,包括通过数组变量使用元素; )实现数组,即在内存里为数组安排一种存储方式,使程序里可以方便地操作它们。当然,最后一个问题主要与语言的实现有关系,在实现C语言系统时,必须确定如何实现数组变量。了解这方面情况也有利于在编程时正确使用数组。
2、数组变量定义
根据数组的性质,在定义数组变量(下面简单说成 “定义数组”)需要说明两个问题: )该数组(变量)的元素是什么类型的; )这个数组里包含多少个元素。C语言规定,每个数组变量的大小是固定的,需要在定义时说明。数组定义的形式与简单变量类似,但需要增加有关元素个数的信息。在被定义变量名之后写一对方括号就是一个数组定义,指定元素个数的方式是在括号里写一个整型表达式。人们常把数组元素类型看作数组的类型,把元素类型为整型的数组说成是整型数组,类似地说双精度数组等。
例如,下面的描述定义了两个数组:
int a[ 0];
double a [ 00];
定义了一个包含有 0个元素的整型数组a和一个 00个元素的双精度数组a 。数组元素个数也称为数组的大小或数组的长度。数组定义可以与其他变量的定义写在一起,例如可以写:
int a [ ], n, a [ ], m;
数组变量也是变量,数组定义可以出现在任何能定义简单变量的地方。数组变量也是变量,在作用域和存在期方面与简单变量没有差别。根据定义位置不同,数组也分为外部数组和函数内的局部数组,包括函数内的静态数组(用关键字static)和普通的自动数组,定义方式(及位置)决定了它们的作用域与存在期。
可以写出数组的外部说明。C语言规定,在写数组变量的外部说明时不必写数组大小,只要在数组变量名后写一对方括号。例如下面是两个数组的外部说明:
extern int a[];
extern double a [];
这两个说明通知本源文件的其他部分,有两个数组(a和a )在其他地方定义,它们的元素类型分别是整型和双精度类型。数组元素个数必须能在编译时静态确定,因此这个表达式必须能静态求值,最简单的情况就是写一个整型字面量(整数)。根据这个规定,下面数组定义不合法
void f(int m, int n) {
int b[n];
….
}
此时局部数组b的大小依赖于函数的参数值,这个值在编译时无法确定。
3、数组的使用
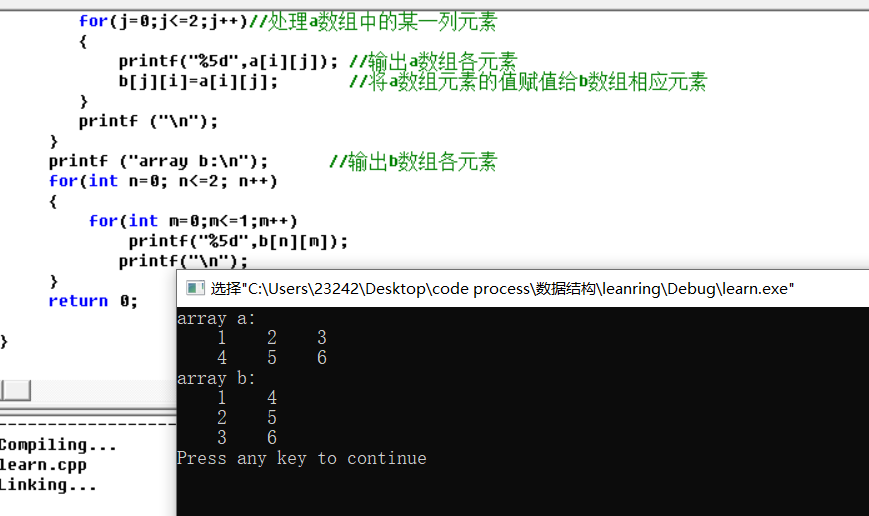
使用数组的最基本操作是元素访问,对数组的使用最终都通过对元素的使用而实现。数组元素在数组里顺序排列编号,首元素的编号规定为0,其他元素顺序编号。这样,n个元素的数组的元素编号范围是0到n-1 。如果程序里定义了数组:
int b[ ];
b的元素将依次编号为0、 、 、 。数组元素的编号也称为元素的下标或指标。
数组元素访问通过数组名和表示下标的表达式进行,用下标运算符[]描述。下标运算符[]是C语言里优先级最高的运算符之一,它的两个运算对象的书写形式比较特殊:一个运算对象写在方括号前面,应表示一个数组(简单情况是数组名);另一个应该是整型表达式,写在括号里面表示元素下标。元素访问是一种基本表达式,写在表达式里的b[ ]就是一个下标表达式,表示访问数组b中编号为 的元素,即上面定义的数组b的最后元素
1 |
|
1 |
|
用户自己建立数据类型
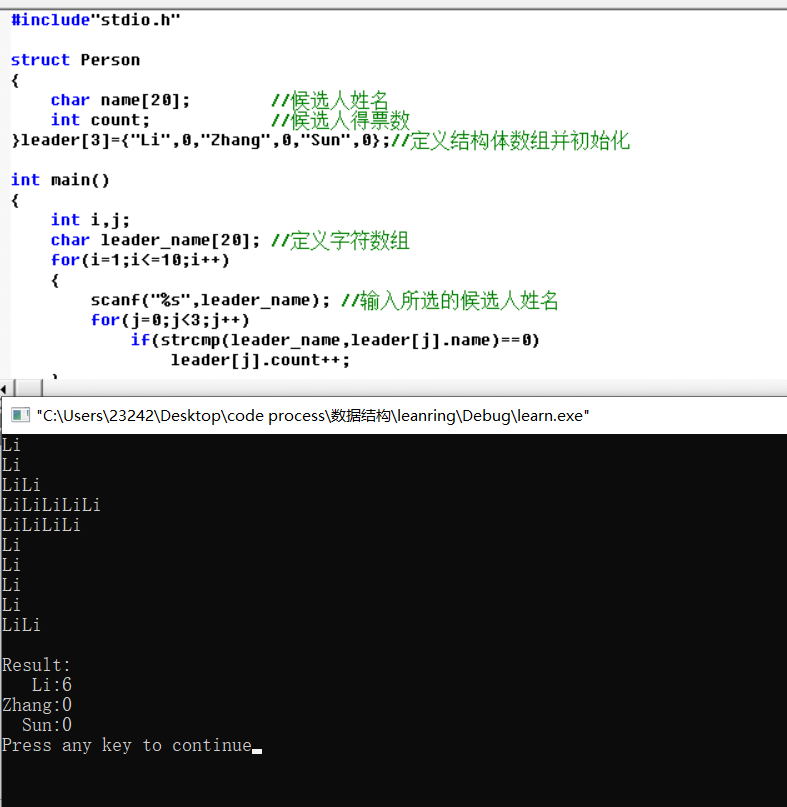
结构(struct)
结构是由基本数据类型构成的、并用一个标识符来命名的各种变量的组合。
结构中可以使用不同的数据类型。
1.结构说明和结构变量定义
在Turbo C中,结构也是一种数据类型,可以使用结构变量,因此,象其它类型的变量一样,在使用结构变量时要先对其定义。
定义结构变量的一般格式为:
struct 结构名
{
类型 变量名;
类型 变量名;
…
} 结构变量;
结构名是结构的标识符不是变量名。类型为第二节中所讲述的五种数据类型(整型、浮点型、字符型、指针型和无值型)。构成结构的每一个类型变量称为结构成员,它象数组的元素一样,但数组中元素是以下标来访问的,而结构是按变量名字来访问成员的。
下面举一个例子来说明怎样定义结构变量。
2
3
4
5
6
7
8
{
char name[8];
int age;
char sex[2];
char depart[20];
float wage1, wage2, wage3, wage4, wage5;
} person;这个例子定义了一个结构名为string的结构变量person, 如果省略变量person, 则变成对结构的说明。用已说明的结构名也可定义结构变量。这样定义时上例变成:
2
3
4
5
6
7
8
9
{
char name[8];
int age;
char sex[2];
char depart[20];
float wage1, wage2, wage3, wage4, wage5;
};
struct string person;如果需要定义多个具有相同形式的结构变量时用这种方法比较方便, 它先作结构说明, 再用结构名来定义变量。
例如:
struct string Tianyr, Liuqi, …;
如果省略结构名, 则称之为无名结构, 这种情况常常出现在函数内部, 用这种结构时前面的例子变成:
2
3
4
5
6
7
8
{
char name[8];
int age;
char sex[2];
char depart[20];
float wage1, wage2, wage3, wage4, wage5;
} Tianyr, Liuqi;2.结构变量的使用
结构是一个新的数据类型, 因此结构变量也可以象其它类型的变量一样赋值、运算,不同的是结构变量以成员作为基本变量。
结构成员的表示方式为:结构变量.成员名如果将”结构变量.成员名”看成一个整体, 则这个整体的数据类型与结构中该成员的数据类型相同, 这样就可象前面所讲的变量那样使用。
1 |
|
文件的输入与输出
C语言是通过将一个文件类型指针与文件关联起来来对文件进行打开、关闭、输入、输出。
文件类型为FILE(实际上是一个结构体)。定义一个文件指针为FILE *fp;就可以将fp和某个文件关联起来进行操作了。例如要打开一个文件:
FILE *fp;fp=fopen(“filename”,“打开方式”);//fopen的返回值为NULL或指向文件的指针或者直接FILE *fp=(“filename”,”打开方式”);如果要重定向只需将指针fp和另一个文件关联。意思是可用一个文件指针操作多个文件。
文件使用完后要及时关闭。这是个好习惯。关闭函数为fclose(fp);这样fp就不在和之前指向的文件关联了。
1.判断文件是否打开成功: www.2cto.com
判断文件是否打开成功可用fopen的返回值if((fp=fopen(“filename”,”r”))==NULL)则打开失败。
2.判断文件是否结束:
判断ASCII文件是否结束fgetc()会返回结束标志EOF(即-1)由于二进制文件数据会出现-1所以必须用函数feof(fp)判断,feof(fp)==1则已结束。
3.单个字符的输入输出:fgetc()和fputc()
ch=fgetc(fp);fp为文件指针,且fgetc()不会忽略空格和回车符,只能用于读入字符。相应的fputc(ch,fp);向文件输出字符时也不会忽略空格,回车符因为fgetc()返回字符所以fgetc()和fputc()通常嵌套使用:fputc(fgetc(in),out)。
fputc()的返回值为输入的字符或EOF(-1)(失败的情况下)
fgetc()的返回值为读入的字符(包括文件结束标志EOF(-1))
4.数据块的输入输出:fread(buff,size,count,fp)和发fwrite(buffer,size,count,fp)buffer是一个指针,对于fread,它是读入数据的存放地址,对于发fwrite它是要输出数据的地址,size是指要读写的字节数,count是要进行读写多少个size字节的数据项。
如果成功fread和fwrite都返回成功输入和读取的数据块个数有可能比count小;
注意:fread参数buffer指向的空间必须大于或等于要读入的数据块大小。
fread和fwrite一般用于二进制文件的输入输出。用于ASCII文件字符发生转换的情况下可能出现与原设想的情况不同。
5.putw()和getw()用来对磁盘文件读写一个整数。
例如putw(10,fp);//返回值为输出的数字(int)
int i=getw(fp);//失败则返回-1
但注意putw()和getw()都是按二进制输入输出的。
所以如果你用putw()输入数据到文件后以文本的方式打开看到的将都是乱码。
同样如果你在文本文件中输入了数字并保存,用getw()来读入的话读入的结果并不是你想象的那样。因为它是按二进制读的
r 打开一个已有的文本文件,允许读取文件。 w 打开一个文本文件,允许写入文件。如果文件不存在,则会创建一个新文件。在这里,您的程序会从文件的开头写入内容。如果文件存在,则该会被截断为零长度,重新写入。 a 打开一个文本文件,以追加模式写入文件。如果文件不存在,则会创建一个新文件。在这里,您的程序会在已有的文件内容中追加内容。 r+ 打开一个文本文件,允许读写文件。 w+ 打开一个文本文件,允许读写文件。如果文件已存在,则文件会被截断为零长度,如果文件不存在,则会创建一个新文件。 a+ 打开一个文本文件,允许读写文件。如果文件不存在,则会创建一个新文件。读取会从文件的开头开始,写入则只能是追加模式。
注意:请确保您有可用的 tmp 目录,如果不存在该目录,则需要在您的计算机上先创建该目录。
/tmp 一般是 Linux 系统上的临时目录,如果你在 Windows 系统上运行,则需要修改为本地环境中已存在的目录,例如: C:\tmp、D:\tmp等。
1 |
|
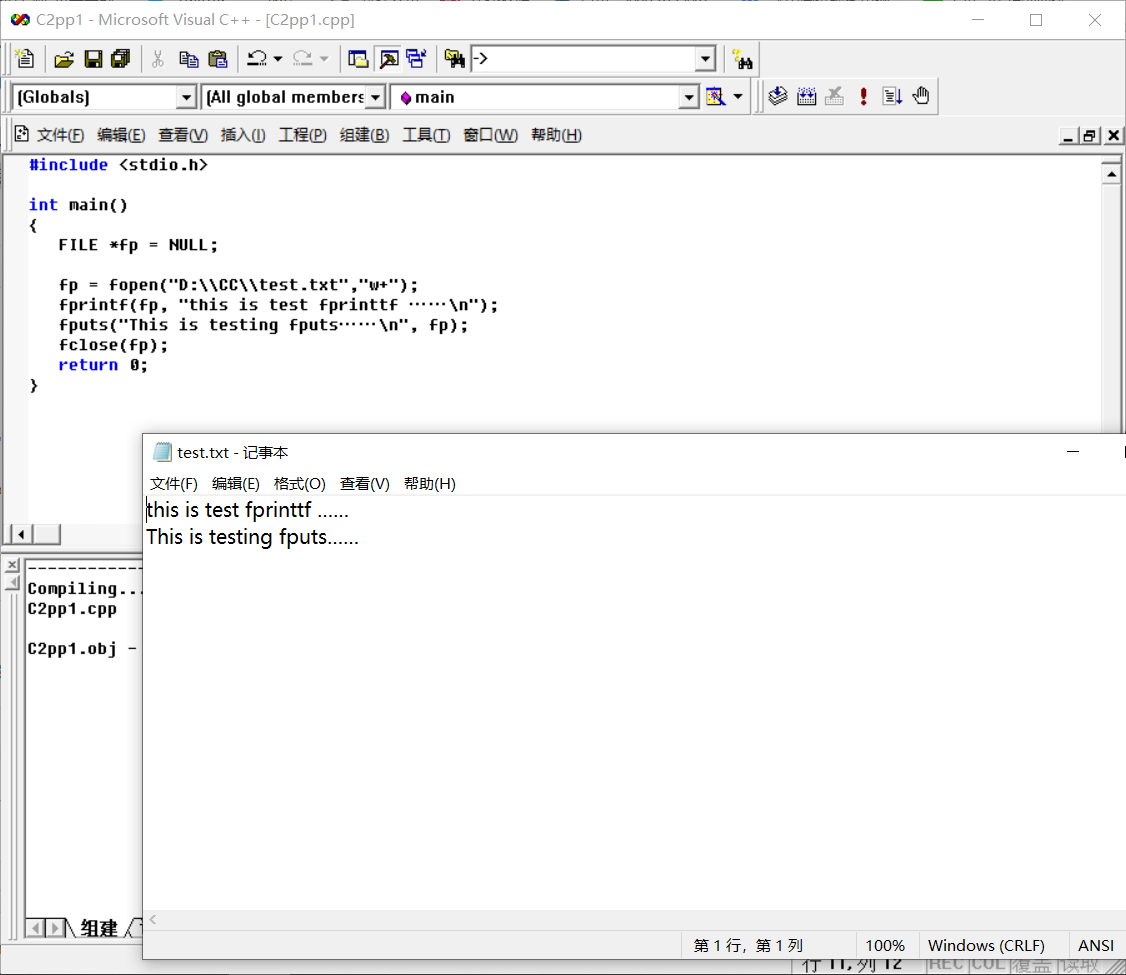
首先,fscanf() 方法只读取了 This,因为它在后边遇到了一个空格。其次,调用 fgets() 读取剩余的部分,直到行尾。最后,调用 fgets() 完整地读取第二行。
1 |
|
1 | #include<stdio.h> |
总结
因为之前学过类似语言,基础学习起来比较快。

